Urządzenia udostępniają obiekty do śledzenia aby sprawdzać czy określony obiekt (adres IP lub host) jest osiągalny lub czy określony interfejs jest podłączony.
Funkcja ta jest przeznaczona m. in do śledzenia HA, interfejsów bądź trasowania.
Aby wyznaczyć obiekt do śledzenia, wybieramy zakładkę Object -> Track Object, naciskamy New, a następnie w oknie Track Object Configuration ustawiamy pola:
Name – nazwa własna obiektu (obowiązkowa)
Threshold – wartość progowa decydująca (w przypadku jej przekroczenia) o uznaniu śledzonego obiektu za nieczynny. Jeśli suma wag awarii poszczególnych elementów śledzonych przekracza podaną tu wartość – cały obiekt śledzony uznaje się za nieczynny.
HA sync – synchronizacja w trybie wysokiej dostępności. Wybieramy, gdy urządzenie pracuje w trybie HA i chcemy, aby ustawienia obiektu śledzonego były identyczne na drugim urządzeniu w klastrze (więcej tutaj: HA – (zabezpieczenia.it)).
Add Track Members – tabela, do której dodajemy i w której precyzujemy elementy do śledzenia dla definiowanego obiektu.
Elementami mogą być interfejsy, protokoły lub określone cechy jakości połączenia.
Track Type -> Interface
Kolejne elementy do śledzenia dodajemy naciskając Add, a następnie w oknie Add Interface Member uzupełniamy pola:
– Interface – interfejs wyznaczony do śledzenia.
– Weight – waga (ważność) ewentualnej awarii/niedostępności śledzonego interfejsu. Może przyjmować wartości od 1 do 255.
Track Type -> Protocol
Kolejne elementy do śledzenia dodajemy naciskając Add i protokół z rozwijanej listy, a następnie w oknie Add [HTTP/Ping/ARP/DNS/TCP] Member uzupełniamy pola:
– IP/Host – adres IP lub nazwa hosta śledzonego na wybranym protokole (dla ARP – tylko IP; dla DNS – nazwa pola to „DNS”)
– Port – numer portu (tylko dla TCP)
– Weight – waga (ważność) ewentualnej awarii/niedostępności śledzonego protokołu. Może przyjmować wartości od 1 do 255.
– Retries – próg ponawiania prób. Jeśli po określonym czasie ponawiania prób nie zostanie odebrany żaden pakiet odpowiedzi, system uzna, że element śledzony jest uszkodzony/niedostępny.
– Interval – interwał czasowy na wysyłanie kontrolnych pakietów. Wyrażony w sekundach – od 1 do 255.
– Egress Interface – interfejs wyjściowy, na ruchu którego śledzimy wybrany protokół.
– Source Object Interface – interfejs źródłowy, na ruchu którego śledzimy wybrany protokół; dla całego obiektu śledzonego (oprócz ARP)
Track Type -> Traffic Quality
Kolejne elementy do śledzenia dodajemy naciskając Add, a następnie w oknie Add Traffic Quality Member uzupełniamy pola:
– Interface – interfejs wyznaczony do śledzenia.
– Interval – interwał czasowy na wysyłanie kontrolnych pakietów. Wyrażony w sekundach – od 1 do 255.
– Retries – próg ponawiania prób. Jeśli po określonym czasie ponawiania prób nie zostanie odebrany żaden pakiet odpowiedzi, system uzna, że element śledzony jest uszkodzony/niedostępny.
– Weight – waga (ważność) ewentualnej awarii/niedostępności śledzonego protokołu. Może przyjmować wartości od 1 do 255.
– Low Watermark – dolny (negatywny) próg śledzenia. Jeśli liczba nowych sesji zakończonych powodzeniem stanie się niższa od podanej wartości, obiekt śledzony zmienia status uszkodzony/niedostępny.
– High Watermark – górny (pozytywny) próg śledzenia. Jeśli liczba nowych sesji zakończonych powodzeniem stanie się wyższa od podanej wartości, obiekt śledzony zmienia status aktywny/dostępny.
TAC
( porada na łącze internetowe o niestabilności trudnej do zdiagnozowania )
Obiekty śledzone po protokołach (tu: ICMP/PING)
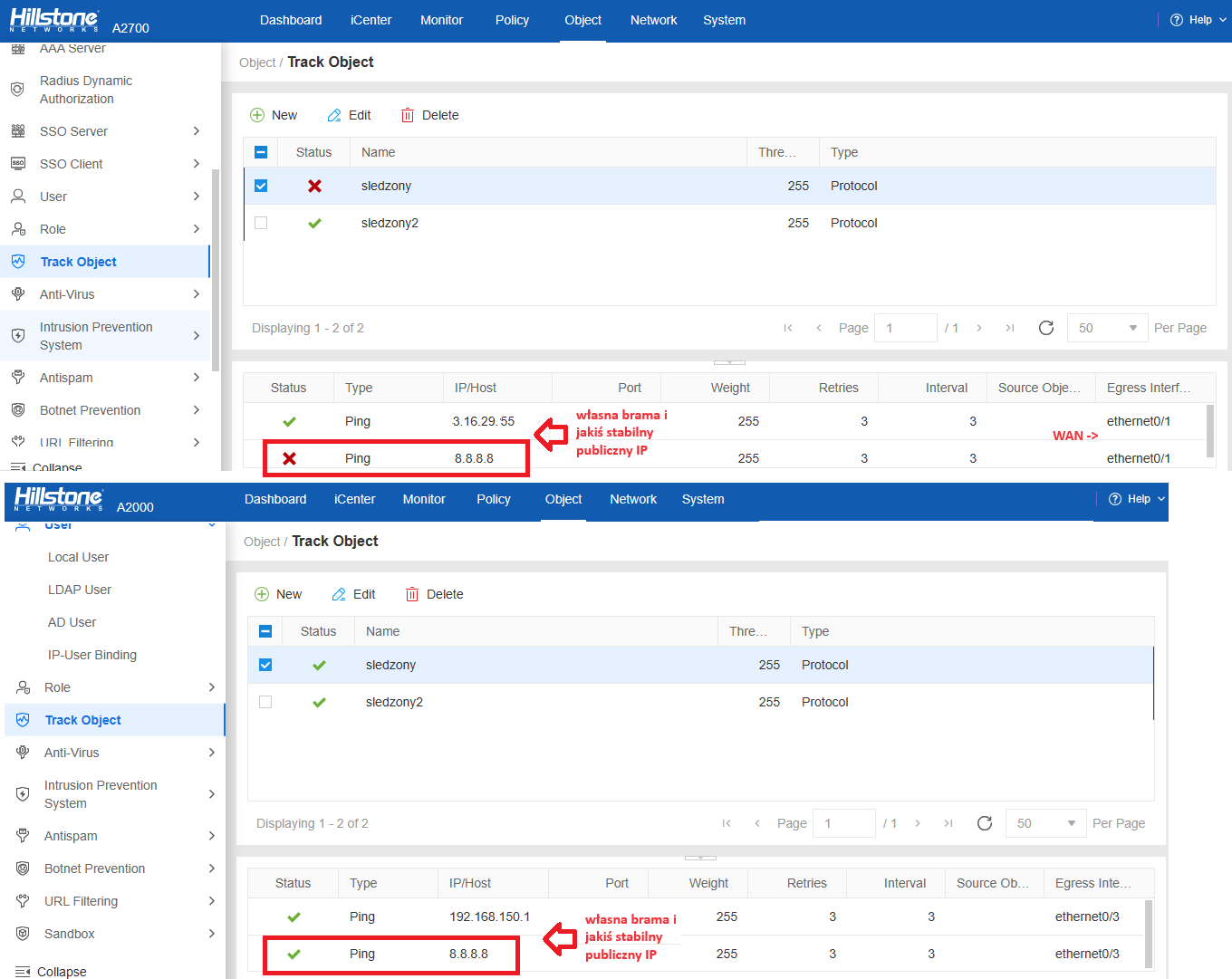
Routing statyczny do śledzenia wybranego adresu.
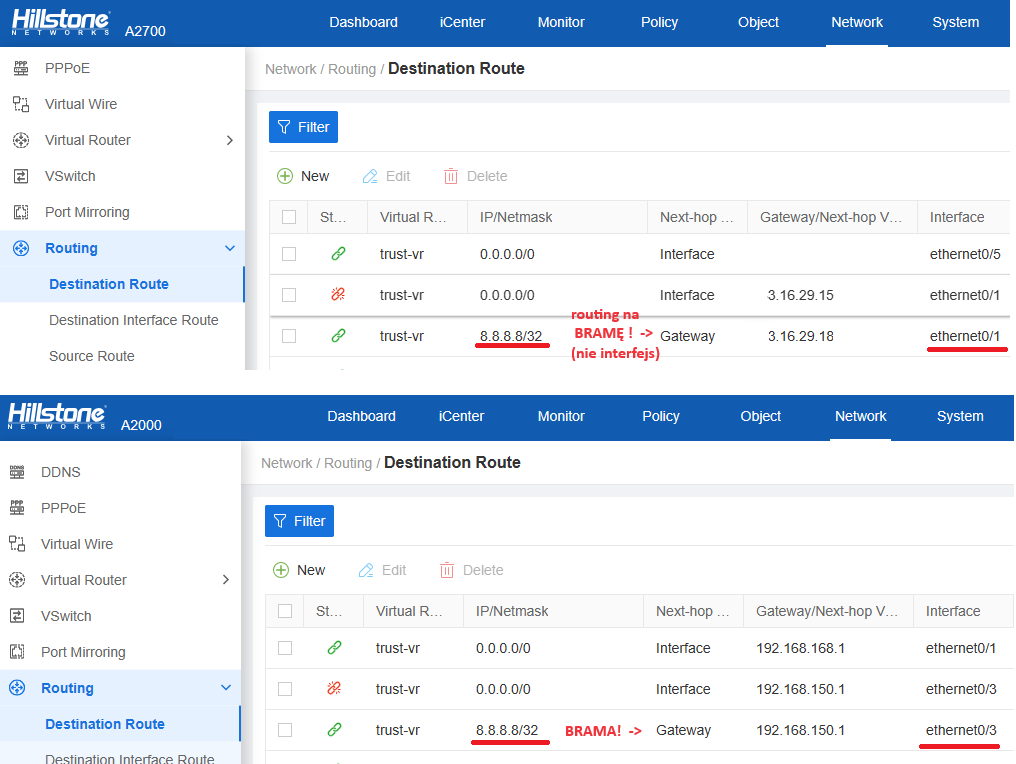
Sposób na automatyczny failover/recover interfejsu:
